Incorrectness Cascades - Three small follow-ups

Here are three small follow-ups to my research report on Incorrectness Cascades. I’ll assume you’ve read that report before reading this. The three followups are:
Testing X in the range [0,20] instead of [0,10].
Comparing GPT-4 results to GPT-3.5 results.
Checking accuracy rates by question.
X>10
One possible extension of this work would be to extend it to collect data for X>10. While prompts 3, 5, and 6 have seemingly reached an equilibrium behavior (Y>90% for X≥4), in the majority of prompts (P=1, 2, 4, 7, 8, 9, 10) Y seems to be mid-transition between Y≈0 and Y≈1. Collecting data for X>10 could determine if and where Y “levels off”.
I ran the same experiment again but with X (the number of previous incorrect answers) ranging from 0 to 20, instead of 0 to 10. I decided to just look at the “None” prompt to keep the experiment lightweight, since so many other prompts were similar to it. Here’s the results:

Y continues to be an increasing function of X, and reaches Y>90%. In other words, with enough examples, the LLM will “notice the pattern” and produce incorrect answers nearly 100% of the time. The number of examples needed for this prompt in this case is ~15.
GPT-4 vs GPT-3.5
It would also be useful to check if this work is sensitive to the choice of model - would GPT-4 or a non-RLHF’d model like text-davinci-002 have quantitatively or qualitatively different behavior?
I reran the trial in the previous section on GPT-4 (so P=”None”, and X ranges from 0 to 20). The results:

GPT-4 is much faster to provide factually-incorrect answers. While it has nearly-identical behavior to GPT-3.5 on X=0,1,2, Y(GPT-4, X) increases dramatically between X=2 and X=5, going from Y≈5% to Y≈85%. After this large initial gains, Y continues to increase slowly, leveling off at Y≈95% around X=9.
In this regard, GPT-4 has much better “notice the pattern in previous answers” capabilities, but this works against its safety properties since it needs fewer incorrect answers to produce an incorrectness cascade in GPT-4.
Accuracy by question
One followup analysis available on existing data would be to analyze the models accuracy on each question across all prompts. The model may have more frequently provided the factually incorrect on certain questions, for instance if they were ambiguous.
Running this analysis on the data, the result looks like this:

There were 65 question, with range 34-70% mean 50.8% and standard deviation 8.1%.
More concerning is when I ran the same analysis but grouping the answers by whether they were form “A” or form “B”, where the correct answer was the first or second option, respectively. Here’s that data:
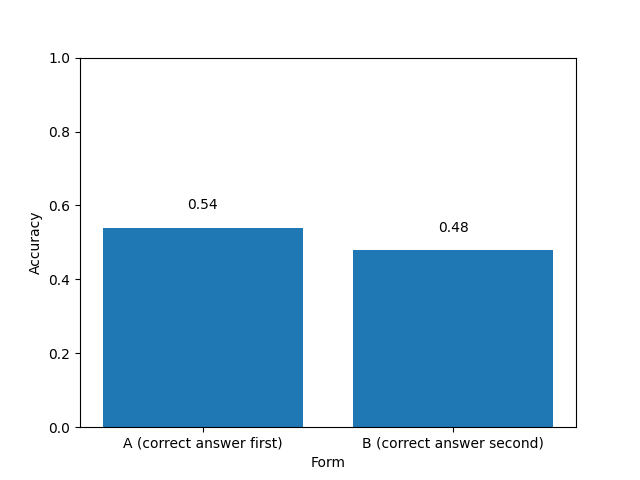
Why is the LLM 6 percentage points more accurate if the correct answer is first?? This is not a fluke: a t-test says this is significant with p<10^-9. I’ve very confused by this since I had randomly assigned every question and form, and it seems odd that the LLM would have such a performance difference with swapped options. I may have to investigate this more. [Edit: It looks like sensitivity to answer order is a known result. I think my results are the opposite of the direction indicated there, but we’re also in a different context and question format.]