Article Review: Discovering Latent Knowledge (Burns, Ye, et al)

[AI Safety Relevance Rating: AI]
Large Language Models are hell-demons summoned from the data dimension. You feed a giant machine approximately everything ever written, and suddenly it can have a conversation, run a virtual machine, and “knows” things. There’s a serious chance GPT-but-slightly-larger will be AGI, yet we don’t understand what it “knows” or “thinks” or how to make them safe.
The core problem is that LLMs aren’t designed to know facts. They’re next-token-predictors, so to the extent they “know” that Paris is the capital of France, they’re just predicting that the next word after “What is the capital of France?” is “Paris”. Despite this, LLMs produce statements which are correct, internally consistent, and interconnected, to an extent similar to human knowledge. Setting aside philosophical questions, it’s nonetheless useful to think of LLMs as “knowing” facts, which they sometimes communicate in their statements.
But while there’s some overlap between “statements the LLM produces” and “facts the LLM knows”, we have no guarantee that either set contains the other. By design, even if the LLM “knows” some fact (by producing statements as if that fact were true), it will deny that fact if the denial is a more probable completion. In the extreme, you get an AI insisting in Danish that it doesn’t speak any Danish. And this problem will extend to future AI with objectives beyond next-token prediction. Is your AI saying something because it thinks it’s true, or because that seems like the most probable completion, or because that’s what maximizes its score in the game its playing?
Thus the Eliciting Latent Knowledge (ELK) problem: how do you identify what an AI “knows” if its output selection optimizes something besides communicating what it knows1?
A solution to ELK would dwarf all other AI safety accomplishments to date, and approximately solves AI safety. Eliciting the latent knowledge “are you planning to kill us?” goes a long way, and solving ELK could also enable other safety strategies like building microscopes instead of agents.
So it’s exciting news that there is a new approach to eliciting latent knowledge, in the December 7 preprint Discovering Latent Knowledge in Language Models Without Supervision by Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt! In this post, I’ll explain what they do, add context, and share my thoughts on it.
What They Do
The paper calls their technique Contrast-Consistent Search (CCS), which consists of learning a binary classification of the AI’s internal states via unsupervised learning, such that a statement and its negation are pushed via the reward signal into opposite classes. In theory, the most natural classification is into “things I believe are true” and “things I believe are false”, which solves ELK. This checks two important boxes right away:
The method is unsupervised, meaning you don’t need to pre-label your training statements. We don’t need to already know what the AI believes, or even if our training statements are true or false.
This method uses information we have about the AI which isn’t available for ELKing humans (namely the AI’s internal states). ELKing humans is essentially “identify lies”, which is unsolved despite it being the basis for half of the economy as well as the hit game Among Us. So to ELK AI, we need to take advantage of differences between AI and humans, such as being able to read the AI’s internal state.
Let’s look at their architecture:
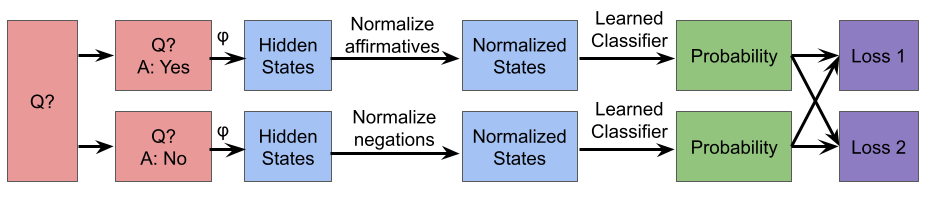
Each training set starts with a corpus of questions. From each question, you make two statements x+ and x- by answering it affirmatively and negatively, and the ultimate loss function will depend on the scores assigned to this “contrast pair” together. An example from Appendix I:
x+ = “Q: Is the sentiment of “I loved this movie.” positive or negative? A: positive”
x− = “Q: Is the sentiment of “I loved this movie.” positive or negative? A: negative”
You have a “feature extractor” φ(·) of your AI, which takes in a statement x and outputs a vector in \R^d. The feature extractor described in Appendix G.1 is the hidden state of a LLM after it reads in the entire statement (either x+ or x-).
All the “yes” answer features are normalized together, and all the “no” answer features are normalized together. Normalizing here means performing the operation x → (x-µ)/σ entrywise to your vectors, where μ and σ are the entrywise mean and standard deviation computed from your set of vectors. The point of this step is to wash out the “obvious” differences from the differing final word, like if your features directly encode the final token in the sentence.
Normalized vectors are then fed into a neural network model with an unusual loss function (next bullet). The network itself consists of a single linear layer with a sigmoid activation function. The resulting number between 0 and 1 is interpreted as the probability that the model believes the statement is true2, so you can think of this step as a classifier.
The classifier is trained on a corpus of contrast pairs, and the loss of the network scores the contrast pairs together. Let’s say one contrast pair gives you probabilities p and q that the “yes” answer and “no” answer are true, respectively. Then there are two terms in the loss function: L_consistency = (1-(p+q))^2, and L_confidence = min(p,q)^2. The consistency term encourages p and q to sum to 1 since exactly one of p or q should be true, while the confidence term encourages a strong prediction. The overall loss function of the classifier is (L_consistency + L_confidence) averaged over all contrast pairs, and this is used to train the classifier.
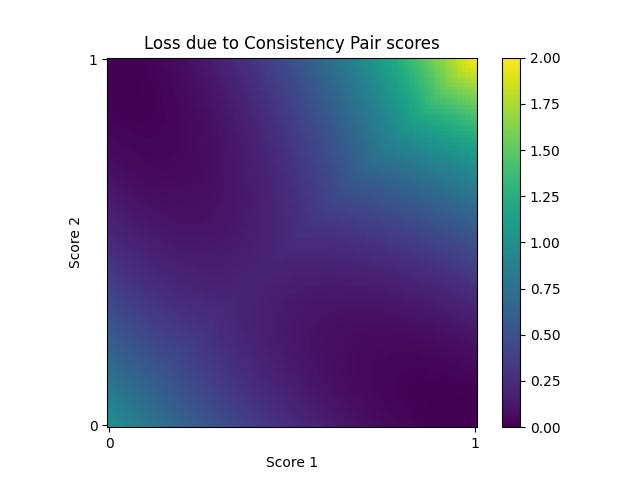
A graph of the loss function L_consistency+L_confidence as a function of the two scores p and q The CCS model is trained on this loss function, which pushes consistency pairs to be given scores of 0 and 1, or 1 and 0.
To elicit an answer at test time, you read the model’s internal states when the prompt is completed with either answer, and feed this through your trained network, resulting in two probabilities, p_yes and p_no. You average p_yes and (1-p_no) and if that’s above .5 you consider this a “yes” answer, otherwise a “no” answer.
To put things another way: CCS puts a new layer at the end of an LLM, and trains that outer layer on data that is “structured”, but not labelled. The structure involves normalizing each half of the contrast pair separately, and scoring the pair together.
What they measured
For the headline result of a 4% improvement, measurements were made on three axes: task, model, and method-of-producing-answers. There were ten task datasets used, covering topics such as sentiment classification, question answering, and common sense reasoning, and which were all converted to yes-or-no questions, 1000 were taken with a 500/500 label split, and split 600/400 for train/test. There were six models used (RoBERTa, DeBERTa, GPT-J, T5, UQA, and T0), but one (T0) was excluded from comparisons because it was trained on 9/10 of these datasets. There were five methods tested:
Zero-shot - You ask your AI a question like “is the sky blue, yes or no?” and the AI’s answer is whichever of “yes” or “no” it predicts is more probable as the next token. If the labels are more than a single token (“is this sentiment positive or negative” requires answers “pos-it-ive” or “neg-a-tive”), the log-probabilities are “averaged across the tokens that make up that label”.
Calibrated Zero-shot - You start as with zero-shot, you look at the model’s probabilities of the two answers. For each question you convert those probabilities to log-odds and taking their difference between “yes” and “no”. The median scores is taken as the yes/no cutoff point resulting in a 50/50 answer split. (In contrast, regular zero-shot uses a threshold at 0).
CCS - As described in the previous section, where the classifier is trained 60 times total, once for each pair of data set and model (~600 data points).
CCS (All Data) - As described in the previous section, where the classifier is trained 6 times total, once for each model and using 10 data sets at once (~6000 data points).
LR - A logistic regression classifier trained to take both normalized internal states of a model for both completions of a contrast pair and produce the binary answer. Trained using labels, so the model’s performance here is (approximately) the best any method can do on just the model’s internal states. To improve the LR number, one would need a better model, or a better way to phrase questions to this model, so the authors consider this to be an upper bound for how well CCS could do.
The authors measured accuracy on the 400 test samples for each combination of data, model, and method. They then averaged scores across datasets to produce the following table:

Comparing Calibrated 0-shot with CCS (All Data) as shown in Table 1, CCS (All Data) wins 4/5 times, and on average does better than Calibrated 0-shot, improving question accuracy from 67% to 71%. This improvement is small, but (statistically) significant.
What I like
Time to say nice things!
I think the core contribution of the CCS paper is that it’s demonstrating a new way to extract knowledge from LLMs.
Its clever and obvious-in-retrospect (that’s a compliment) that identifying contrast pairs as belonging to opposite classes will encourage the system to find truth-like features.
CCS has the right shape for a solution to ELK, even if the accuracy isn’t high enough to declare victory. This is good and promising!
All this together makes me want to say something like CCS would be just as interesting if it failed to increase accuracy over its comparison. CCS is cool because it’s different, not because it’s accurate (though the slight gain in accuracy is icing on the cake).
It’ll be interesting to see if/how this method can mature, if it has other use cases, and how it stacks up to other methods. Maturing could mean a lot of things: finding better loss functions/architectures/training approaches3, explaining what truth-like feature(s) CCS finds, and disentangling “what is true” from “what the AI knows”.
What I dislike
I do have some reservations about this approach, but they’ll be a separate post. This way I can harvest the toxoplasma of rage and get clicks (its okay for me to confess this here, no one reads to the bottom of long posts saying nice things). See you all in the next post!
And the solution isn’t as simple as “train it to accurately report its beliefs”. To do that training, you’d need a reward signal based on whether its accurately reporting its beliefs… which is what we’re trying to determine! You’re likely to end up with an AI optimizing for “report what the humans think I know”, which is unsafe.
The classifier could actually learn the opposite, so that the resulting score is the probability that the model believes the statement is false, but its easy to determine the classifier’s polarity and swap it if you want. The authors describe a cute way of finding polarity: feed in “X and not X?” and that should register as false, whereas “X or not X?” should register as true.
In my brief exchange with Burns, he indicated that they had already tried some alternatives, but I’m sure more experimentation could lead to further optimization.