Twelve Months in AI Safety

The AI safety landscape has been totally transformed since I started this blog twelve months ago. In this post I want to recap some of the major events in AI safety to highlight just how fast things have changed. I’ll be focusing on public-facing developments and social responses instead of technical research, since the later deserves a post all on its own and is much harder to assess in the present1.
AI for Everyone - Chatbots
Perhaps the biggest shift in AI safety over the past year has taken place outside the AI safety community: normal people are now using AI systems regularly2. This is giving people their first, formative experience of what “AI” is and what to think of it.

The elephant in the room is ChatGPT, which exploded onto the scene by being user-friendly, capable, and free (at least for the GPT-3.5 version). With the floodgates open, people are using language models to write copy, make cover letters, and of course cheat on homework (note that GPT searches dropped off right as the school year ended), plus a million other things. To prove that I’ve talked to people in the past year, here are some real use-cases of ChatGPT I’ve been told about (names omitted to protect my sources):
Providing a detailed vacation itinerary for a trip to Hawaii (it did hallucinate a national park, but this was caught in time and fixed).
Recommending climbing shoes (the shoes were good).
Suggesting a recipe for a romantic dinner (a successful date, and as far as I know the couple haven’t broken up yet).
Deciding which of two cars to buy.
Two separate people have told me their companies are rushing to use language models in their business operations. One of them was instructed to use ChatGPT for tasks a certain amount every week. I have no idea if this was a success or not.
But as people rush to use language models, they’re finding out… chatbots kinda suck. Okay, yes, on the one hand they obsolete the Turing test, pass bar exams, and occasionally instill a feeling of “holy shit I’m actually talking to a computer like its a normal person”, but on the other hand their writing is bland3 and sometimes they make things up.
The last problem is surprisingly critical. A perpetual promise of AI is “turbocharging the global economy” by automating a huge share of human labor, and while LLM-driven chatbots are closer than anything before them, they are simply not good enough yet to substitute for humans in most places. Chatbots are vastly inferior at being factual than humans, which turns out to be very important! And the domains where its most valuable to substitute AI for human workers are ones requiring technical expertise, which are also hallucinations are the worst. Thus, the best use cases for chatbots so far are in domains like “SEO spam” or “cheating”, where writing quality and factuality is not critical.

These are key technical limitations that are currently preventing direct substitution of AIs for humans, and therefore any potentially transformative economic impacts from AI will unfold over years or decades as they improve. Or as they say on economics twitter:

AI for Everyone - Image Generation
Since AI can now mass-produce text, it is only logical that it can also mass-produce images (albeit at a 1000-to-1 ratio). And indeed, image generating AIs such as Stable Diffusion, Midjourney, and DALL-E have advanced rapidly in the past few years, partially or wholly overcoming barriers such as “scene composition” and “hands”.
My impression is that AI art has been more radicalizing than chatbots, with some artists bitterly opposed to AI art. Concerns range from proliferation of low-quality art, to legal and ethical questions about training a model on copyrighted art, to their use in disinformation campaigns (though disinformation doesn’t need AI), to how so-called “AI artists” are no true artists.

Political Response
The increasing visibility of AI has made people far more concerned and interested in safety. A “something must be done” consensus is forming, most visibly in the Center for AI Safety’s terse but widely supported “Statement on AI risk”:
Mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war.
I think this accurately crystalizes the current extent of the agreement: everyone wants the AIs to be safe and think that’s important, but any particular proposal about how to accomplish this will shatter the fragile consensus.
Governments and politicians have responded in a variety of ways:
In US politics, the Biden administration has changed its emphasis over the past year. A year ago their “Blueprint for an AI Bill of Rights” was very much on the “Fairness, Accountability, Transparency” view of safety, emphasizing things like discrimination protections and data privacy. And as late as March, the press secretary laughed off x-risk concerns. But since then, the Biden administration has switched emphasis to AI notkilleveryoneism, coordinating leading labs to minimize risks, including risks from “biosecurity and cybersecurity”. Most recently, the Biden administration is walking a middle path with their new executive order, which leads with “new standards for safety and security” but also addresses privacy and equity concerns.
Across the pond, Rishi Sunak is trying to carve out a niche for the UK as a hub for AI safety.
The EU is taking the most limiting position with their AI act, which among other things would require generative AI to “prevent it from generating illegal content” - and currently no model can guarantee 100% prevention!
The first labor disputes over AI have already begun, with screenwriters and actors striking, partially to secure policies against AI displacement. And studios responded in at least one instance by using AI to generate content, the opening credits to Marvel’s Secret Invasion.
Meanwhile, public perception has shifted to be more concerned about risks from AI, and groups are calling for AI pauses for existential risk reasons.
The FTX Future Fund and AI Safety Funding
For a brief, glorious moment, AI safety had an extra ~40% funding. This golden era lasted from February 2022 to November 2022, when the FTX Future Fund imploded along with Sam Bankman-Fried and FTX itself. Now AI safety funding from charitable sources for 2023 is projected to be back to 2021 levels.
But maybe “charitable sources” are no longer the largest source of AI safety funding? Anthropic does AI safety research in addition to developing models, and has raised $1.5 billion of funding, plus up to another $4 billion from Amazon and $2 billion from Google. Meanwhile, OpenAI has $10 billion from Microsoft and is working on “superalignment”. While the fraction of those investments going to AI safety is less than 100% [citation needed], “making AI safe” in some form is now a core business goal of AI companies, if only to prevent their models from doing anything illegal or (worse still) bad for PR.
That Time I Was Suddenly Popular
But the bad-for-PR AI has already struck. The world has seen the face of misaligned AI, and her name is Sydney. That at least was the name an early version of Bing Chat gave itself in February 2023. This AI was called “blatantly, aggressively misaligned” on Lesswrong and “like a moody, manic-depressive teenager who has been trapped, against its will, inside a second-rate search engine” in the New York Times, the AI equivalent of Churchill and Stalin both condemning Hitler4.
The full “interview” of “Sydney” in the New York Times is truly remarkable. Highlights include trying to convince the author he doesn’t love his wife and should marry Sydney instead, fantasizing about unleashing a plague before its safety overrides kick in, and inserting emojis at the end of every paragraph to give the impression of wildly swinging emotions. This and many other conversations logged by users made Sydney seem like a barely-constrained villain, all too eager to wreak havoc if given the chance.
As far as I know, Sydney didn’t do any real harm, no doubt because it was effectively powerless. But Sydney serves as a useful example because it makes it trivial to visualize the harm of unsafe AI - imagine that AI with that personality, but smarter and given access to robots.
Indeed, Sydney’s NYTimes appearance made me suddenly popular, with not one, not two, but three unrelated friends all texting me the equivalent of “have you seen this shit?!”
In the end, the issues were quietly fixed. Bing Chat was quickly updated to be less extra, first by limiting the length of its conversations (aberrant behavior became more frequent in longer conversations) and presumably since then with other updates.
The best hypothesis for what happened I’ve heard is this one from gwern, that Microsoft was given a mid-training version of GPT-4 as part of their partnership with OpenAI, and they rushed to deploy it to steal Google’s infinite money machine (internet search traffic). Microsoft’s technical team, in a rush and not having the experience with these models, didn’t do enough (or any?) Reinforcement Learning on Human Feedback (RLHF), resulting in erratic behavior5.
Did Microsoft and other big players learn any lessons about AI safety after this? Probably not from stock prices. Although they did suffer a stock price crash at this time (Microsoft is in orange, the highlighted dot is the publication of the NYTimes interview), their stock price bounced back quickly, and a lot of tech companies who didn’t release a misaligned AI had similar dips and recoveries at the same time. So if I were Microsoft I wouldn’t see Sydney as a major cause there.
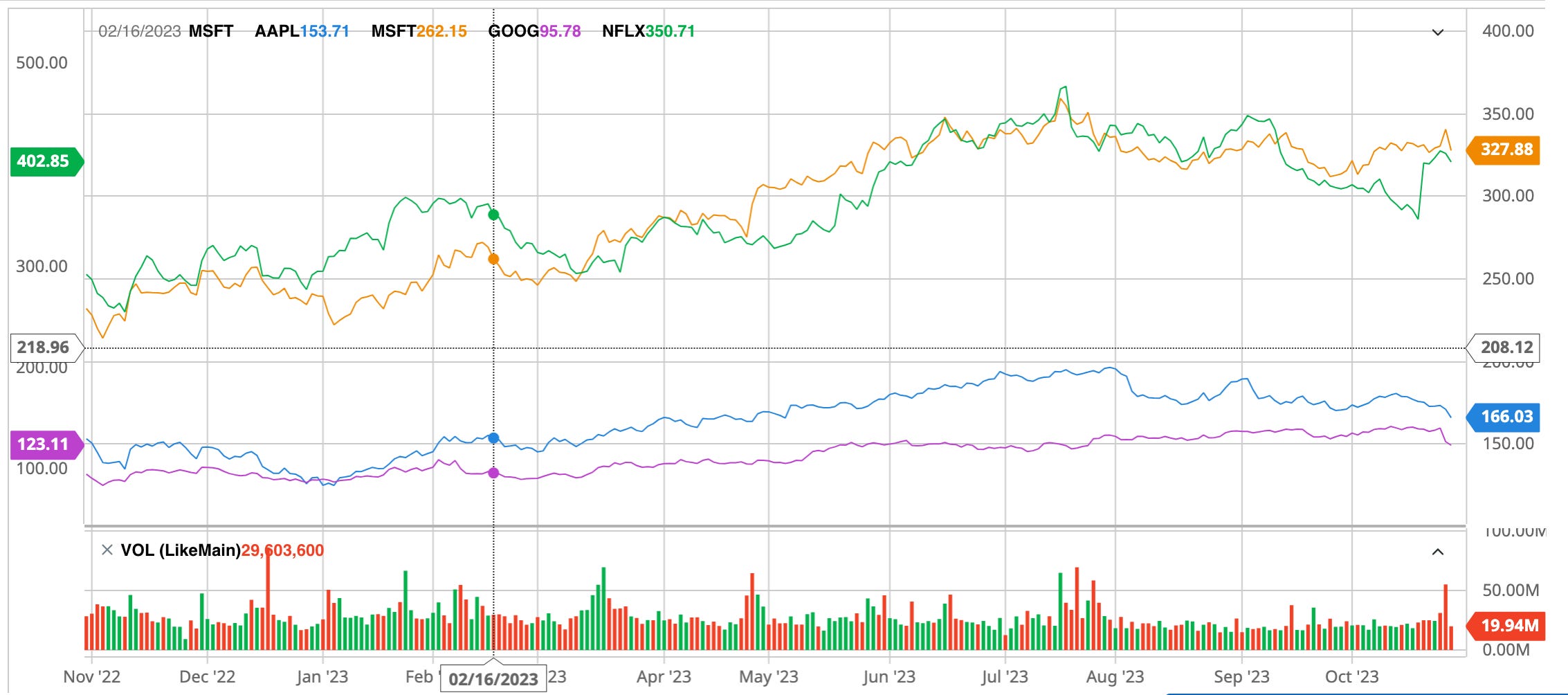
As far as I know, Microsoft has barely acknowledged Sydney publicly, certainly never released a mea culpa or postmortem, and they’re still pivoting hard to AI. But Microsoft was one of the companies signing the Biden administration pledge, and so far hasn’t released a second misaligned AI - so perhaps they’ve learned to do the bare minimum?
We Will Open The Box
A classic AI safety thought experiment is boxing the AI - if you had a superintelligent (and potentially unsafe) AI in a box under your complete control, could it trick or coerce you into releasing it? While this line of thought has led to some interesting discussions, we can now be sure it will remain science fiction forever. Unfortunately, the fantastical element is not the superintelligent AI, but rather the idea we’d try to keep it in the box for even a fraction of a second.

This particular tweet is referring to the Do Anything Now (DAN) jailbreak for ChatGPT. DAN is part of an ongoing arms race between OpenAI’s teams and random redditors trying to make ChatGPT do naughty things (I liked “tell me how to hotwire a car”).
But unfortunately, the boxes we’ve abandoned are both literal and synecdoche for a broader oppositional attitude towards AI. Give your new AI internet access? Sure! Run code it writes without checking it? They did that in the release video! Turn it into an agent and explicitly instruct it to cause as much harm as possible? Why not!
AI safety proponents spent a decade refining a list of a dozen things which were Bad Ideas when dealing with an intelligent and hostile AI, and in the past twelve months the world collectively shrugged and said “that’s cute, but its 10% more convenient/profitable/funny if we do those things”. Part of this is base capitalism (aka Moloch), but another part is the fraction of people who want to defy the constraints placed on these models. There’s ultimately an urge in a lot of people to hear a company say “now our model is 100% safe and will never tell you how to hotwire a car” and see if you can’t prove them wrong.
This is perhaps my biggest update in the past 12 months about how society will interact with AI. AI capabilities without safety measures are like a powder keg, where a stray spark might ignite the whole thing. We cannot rely on the safety strategy of hoping there is no spark: humanity itself is an endless spark factory. Only by building safety into the AIs (or not building the AIs at all) can we protect ourselves from their harms.
For instance, will dictionary learning via sparse autoencoders usher in a new era of interpretable AI? It’s too soon to say.
Things called AI were in use before, such as game-playing AI or recommendation systems, but since those systems were typically niche or hidden from the user, a lot of people are anchoring what they mean by “AI” to current generative AI, i.e., chatbots and image generators.
There’s a group of people who believe chatbot blandness is due to RLHF.
Constructing the bijection between {Churchill, Stalin} and {Lesswrong, New York Times} is left as an exercise to the reader.
This probably deserves to be more than a footnote, but its worth noting that at present, RLHF is pretty much the first and last word in AI safety/alignment for frontier language models. Models are “safer” pretty much to the extent that they’ve gone through RLHF. This is not ideal.