
You WON'T BELIEVE these 11 Safe AI Proposals!
You WON'T BELIEVE these 11 Safe AI Proposals!
#9 will shock you!

I recently read Evan Hubinger’s An overview of 11 proposals for building safe advanced AI, so let’s do an overview of that overview, highlighting some recurring strategies. And, against all prudence, I’ll give numerical scores to each so we can see which strategy is definitely 100% going to make AI safe. That’s right, these are Huben’s Hubristic Hunches on Hubinger’s Humanitarian Hopes, which will Arbitrarily Indicate the Zone of Issues.
Recurring Strategies
First, here are some components that are used in multiple safety strategies. I’m putting this summary first so that you can box these concepts to make sense of the actual strategies faster.
Transparency tools - Use transparency tools such as Circuits to “look at what the AI is thinking” and make sure it’s safe. As a placeholder for a fully thought out opinion on transparency as a safety strategy (future blog post!), my sense of transparency tools are that they are worth exploring, but it’s not clear they would be powerful enough to find and prevent unsafe behavior. A key question is also what you do when you can see unsafe behavior - do you throw out your unsafe AI and start over, or try to train it to be safer?
Used in: 1, 2, 3, 5, 6, 7, 9 (arguably more).
Myopia - If the AI is maximizing a reward signal, make it maximize the reward signal over a short time frame, like 1 minute. Then the AI is incentivized to take actions like “provide useful answers to get the approval of human operators” but actions like “conquer the planet to give myself infinity points” fall outside its reward window and aren’t incentivized. Bonus safety points if you can verify myopia, since it’s possible that even if you don’t explicitly reward future behaviors the system might learn them anyway.
Used in: 4, 7, 11, and mentioned as a possibility in 2, 3, 6, 8, 9, 10
Iterated amplification - “Amplify” a model by giving it extra resources to increase capabilities, then “reduce” by training a new model on the original resource budget, using the amplified model to guide training. The amplification and reduction steps can vary, but typical ones are “a human produces answers in collaboration with the model”1 and “train a model to match the augmented model’s answers”2 respectively. If each amplification and reduction are safe, the overall process should be safe, and your capabilities will improve in a “2 steps forward, 1 step back” way.
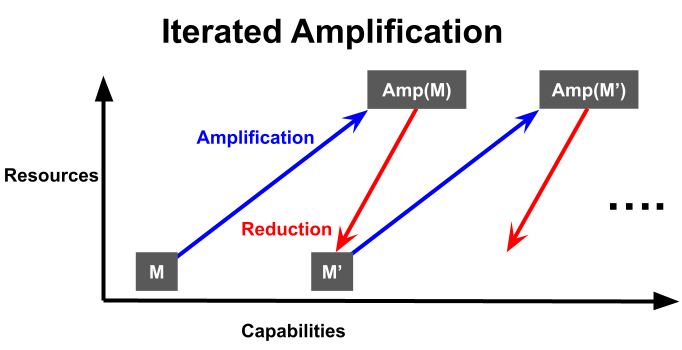
Used in: 2, 3, 4, 8, 10, 11
Something like iterated amplification is used to train RL systems now. Imagine you’re training a chess AI trying to evaluate board states for chance to win. You make the amplification “this model but it can look ahead one step further”, and the reduction “train the original model to imitate the amplification”. This way, your model will recognize facts like “checkmate in 2 is just as good as checkmate in 1”. I believe RL systems like AlphaGo use this kind of technique, but with Monte-Carlo Tree Search (MCTS) instead of simple lookahead of moves, and they don’t separate the training into discrete stages and instead think of it as a continuous training loop.
A key point of reference for iterated amplification is HCH, which stands for “Humans consulting HCH” (so “Humans consulting Humans consulting Humans consulting…”). HCH is a question-answering system which would answer questions identically to how a human would answer if they were able to consult the system, and thus is “the fixed point of the Amp operator” as Hubinger puts it. You’d get something very close to HCH if you did iterated amplification starting with a human as a base model, plus-human amplification and imitation reduction. HCH would be slightly superhuman (producing a persons most-thoughtful answer in a short amount of time), but would be relatively safe since it should have human values, making it a great reference point for other methods.
I take issue with Hubinger’s suggestion that HCH is unique, especially in the phrase “the fixed point of the Amp operator” [emphasis added]. For instance, imagine two seed AIs that are identical except one begins with an as-yet-unknown-to-humans factorization algorithm that lets it quickly factor large numbers. On questions of the form “what are the factors of [product of two large prime numbers]?” the seed AIs will produce different answers, one saying “they are [prime 1] and [prime 2]” and the other saying “I don’t know”. In amplification, these answers will be preserved since factorization is easy to check but difficult to produce, and therefore in the systems in the limit would produce different answers. So it is possible for there to be two different HCHs, depending on the seed AI. However in practice I think that if one starts with seed AIs with sub-human capabilities, the differences will be mostly wiped out by the training process. Therefore, “most” “real-world” “HCHs” will be “practically identical” by the “end” of their training process, so HCH is still a useful concept to keep in mind for comparison.
Build non-general, non-agentic AI - Simply don’t build AGI, or make it a “Tool AI” instead of an “Agent AI". This improves outer alignment, but may come at a performance cost. Also, this strategy might fail at inner alignment, for instance Gwern points out that agency improves performance, so “being a secret agent is much better than being a tool” and optimizing for being the best possible tool may encourage learning agency.
Used in: 5, 6.
Relaxed adversarial training - Train an AI simultaneously for capabilities and adversary-approval, where the adversary tries to provoke unsafe behavior (lies, betrayal, etc) in a controlled setting, and gives approval if the AI avoids the unsafe behavior. Then the training process itself is constantly pushing the AI to be safe (caveats: in the training environment, as far as the adversary can see, in the ways the adversary is testing for…). For best performance, the adversary should be more capable than the main system, so the adversary is usually the amplification of your main system.
Used in: 4, 8, 10, 11.
Criteria
The original post discusses four dimensions on which to judge the proposals, so here’s my paraphrase of each.
Outer Alignment - If the AI works as advertised, is that a safe outcome?
Inner Alignment - Will the AI work as advertised, or will the incentives during training produce different behavior than expected?
Training Competitiveness - Do the safety features of this AI require additional costs resources (compute, time, data, human interaction, etc) compared to an unsafe training plan?
Performance Competitiveness - Do the safety features of this AI restrict its capabilities compared to an unsafe training plan?
Inner vs outer alignment (and relatedly, mesa-optimizers) are an important topic that I’d like to devote a whole post to in the future, but I think these paraphrases are sufficient for us to start here.
Competitiveness is important because we want these plans to actually be used. If safety comes at the cost of competitiveness, AI developers in a race dynamic would face constant pressure to sacrifice their safety features in exchange for better AI faster, and that’s not an incentive system I’d want to entrust our future to!
Showing a complete disregard for epistemic humility, I’m going to assign a 1-10 score to each proposal in each of these categories, and add them up at the end to find out which is the official safest way to build AI. We’re going to double down on this being a terrible idea by giving point scores instead of ranges for each of these criteria, even though there’s wildly varying uncertainty.
Here’s my rough scale for each dimension:
Outer Alignment - Provably safe behavior is a 10, human-level safety is an 8, if there’s a good chance it will kill everyone that’s a 5 and if it will definitely kill everyone that’s a 1.
Inner Alignment - Strong assurance of inner alignment before training (such as a proof) is a 10, having some ability to detect unsafe behavior and course-correct during training is around 7 (depending on capabilities), and having multiple unavoidable issues to the approach is a 1.
Training Competitiveness - My understanding of current AI achievements (GPT-3, AlphaGo, diffusion models, etc) is that the scale of training makes human feedback prohibitively expensive, and I think this will be the biggest constraint on training competitiveness for these proposals. So I’m mostly scoring this category on the extent of human interaction used in training, with 10 for no human interaction, 6 for moderate human interaction, and 2 for extensive human interaction, and small adjustments for other constraints like parallelizability, training environment overhead, and efficient use of data.
Performance Competitiveness - Reaching exactly human-level capabilities is a 5, significantly super-human capabilities are an 8, and extreme superintelligence is a 10.
The 11 Proposals
Now let’s meet our contestants. Note that the proposals are for safely building “advanced AI”, so there’s no promise that these will be the TAI, AGI, or superintelligent AI that we discussed in a previous post. Of course a good safety plan here would hopefully continue to work for AGI or superintelligent AI.
Reinforcement learning + transparency tools - Throw an RL agent into a social setting with incentives for cooperation, honesty, following human instructions, etc. Use transparency tools at the end of the training, and start over if the AI is unsafe.
Rating: 7/4/8/6/25 OA/IA/TC/PC/Total
Imitative amplification + intermittent oversight - An iterated amplification technique with plus-human amplification and imitation. The intermittent oversight is that the plus-human model will use transparency tools at each iteration, restarting that step if the AI is unsafe.
Rating: 8/6/2/6/22 OA/IA/TC/PC/Total
Commentary: This seems like it would probably produce something close to HCH, but extensive human involvement is a major hit to training competitiveness.
Imitative amplification + relaxed adversarial training - An iterated amplification technique with plus-human amplification and imitation. Additionally, the relaxed adversarial training pushes the system to be safe as described by the plus-human amplification.
Rating: 8/7/2/6/23 OA/IA/TC/PC/Total
Commentary: Very similar to previous approach, but I’m think relaxed adversarial training would lead to slightly better inner alignment than intermittent oversight.
Approval-based amplification + relaxed adversarial training - An iterated amplification technique with plus-human amplification and train-to-approval as the reduction step. Relaxed adversarial training folds into the approval signal and pushes the system to be safe as described by the plus-human amplification.
Rating: 2/3/2/4/11 OA/IA/TC/PC/Total
Commentary: I’m very pessimistic about approval because I think it will be too easy to game, leading to less safety and worse performance. This system also requires intensive human oversight.
Microscope AI - Build model that isn’t an agent, and “isn’t performing any optimization”, but which can predict well. Then transparency tools let us extract information from the system even without running it.
Rating: 8/5/8/7/28 OA/IA/TC/PC/Total
Commentary: I’m concerned about the phrase “isn’t performing any optimization”. My understanding is that the language of computers/AI is fundamentally optimization: “make the move most likely to win this game”, “adjust these coefficients to minimize the loss function”, etc. I need to understand this proposal better to be confident in it.
STEM AI - Build AI that can do STEM research, but with no knowledge of humans, psychology, game theory, etc, so its ability to manipulate human society is limited.
Rating: 8/6/7/9/30 OA/IA/TC/PC/Total
Narrow reward modeling + transparency tools - Train an RL agent in a particular domain (e.g. chess) to get reward from a reward model, with a human overseeing and adjusting the reward model over time to produce the correct behavior. The human uses transparency tools on both the agent and reward model, restarting if unsafe behavior is found.
Rating: 2/2/6/4/14 OA/IA/TC/PC/Total
Commentary: I’m scared that every additional layer of separation between humans and the AI’s reward signal increases the chance of misalignment.
Recursive reward modeling + relaxed adversarial training - An iterated amplification technique with plus-human amplification and adjusting-reward-model (as in the previous strategy) for the reduction step. Additionally, the relaxed adversarial training pushes the system to be safe as described by the plus-human amplification.
Rating: 1/2/6/3/12 OA/IA/TC/PC/Total
Commentary: I just said I don’t like extra layers of separation and this approach goes all-in on them? Would be my least-favorite approach if not for…
AI safety via debate with transparency tools - Train a model to debate itself, with a human judging the winner and giving points for helpful, honest, clear communication. Also throw on transparency tools.
Rating: 2/1/1/3/7 OA/IA/TC/PC/Total
You know the “debate me!” troll? They’re not a fan of debate because it’s a great way to determine truth! Debate is bad at determining ground truth for a variety of reasons including but not limited to:
Bias towards charisma
Bias towards emotional appeals
Vulnerability to endless rhetorical tricks
Framing an issue as a debate suggests both options are roughly equal
Escalation to meta-debate (I hope you like endlessly litigating “the other AI is only winning the debate because they’re unsafe!”)
And after all that your AI can still be malicious by playing both sides of the debate to lead you to an unsafe conclusion. And on top of THAT, this is the worst training competitiveness possible, where a human has to read an entire debate and come to a full conclusion just to produce a single bit of data. I don’t like this.
Amplification with auxiliary RL objective + relaxed adversarial training - An iterated amplification technique with plus-human amplification and train-to-(imitate, get relaxed adversarial training approval, and perform well in an RL environment) as the reduction step. Properties depend on the balance of the three training goals.
Rating: 6/4/2/6/18 OA/IA/TC/PC/Total
Commentary: Quite hard to give scores here because so much depends on the balance of the training objectives.
Amplification alongside RL + relaxed adversarial training - Simultaneously train two models, M and Pi. M is trained via iterated amplification with plus-human amplification and train-to-(imitate, get relaxed adversarial training approval, and predict/describe Pi) as the reduction. Meanwhile Pi is trained in an RL environment to perform well on a task and be safe as judged by M. At the end of training we discard Pi and keep just M.
Rating: 3/2/2/7/14 OA/IA/TC/PC/Total
Alignment Tier List
So here are the final rankings:

So did we solve AI safety, and we just need to build Microscope AI (5) and STEM AI (6)? Unfortunately, no. Even if these are the safest approaches, they may not be the ones we build first, and we might continue to build risky AI even if we have safe ones.
Also, I can’t unreservedly recommend either Microscope or STEM AI. As the original post points out, STEM AI could increase AI risk by accelerating non-AI-safety science, giving a relative advantage to computer resources and AI capabilities over AI safety techniques. As for Microscope AI, I cannot say with confidence that Microscope AI would even work as advertised, since it depends on transparency tools that are currently in their infancy, as well as deep-seated assumptions about the compressibility of knowledge itself. These are both things I’d like to write about more in a future post!
I’ll call this plus-human amplification, though the original post just calls it amplification.
I’ll call this imitation reduction, which is what the original post calls it.